


Resumen del artículo
Por qué importa este artículo
Confundir Rules, `CLAUDE.md`, Commands y Skills no es un detalle de estilo. Satura la ventana de contexto, empeora la recuperación del modelo y abre brechas de seguridad reales. En este artículo bajo la diferencia a tierra: dónde encaja cada mecanismo, cómo decidir rápido en equipo y qué amenazas aparecen cuando tratamos estos archivos como si fueran documentación pasiva.
Seguir leyendo
Más en el archivo
Artículo más reciente
La Anatomía Técnica de la Extracción de Modelos en 2026 (El Gran Robo del Siglo?)
Un análisis técnico profundo sobre los ataques de Extracción de Modelos. Vamos a ver un poco de las matemáticas detrás de la 'Destilación de Conocimiento', los pipelines de recolección de logits y las fallas criptográficas de las marcas de agua en LLMs.
Artículo anterior
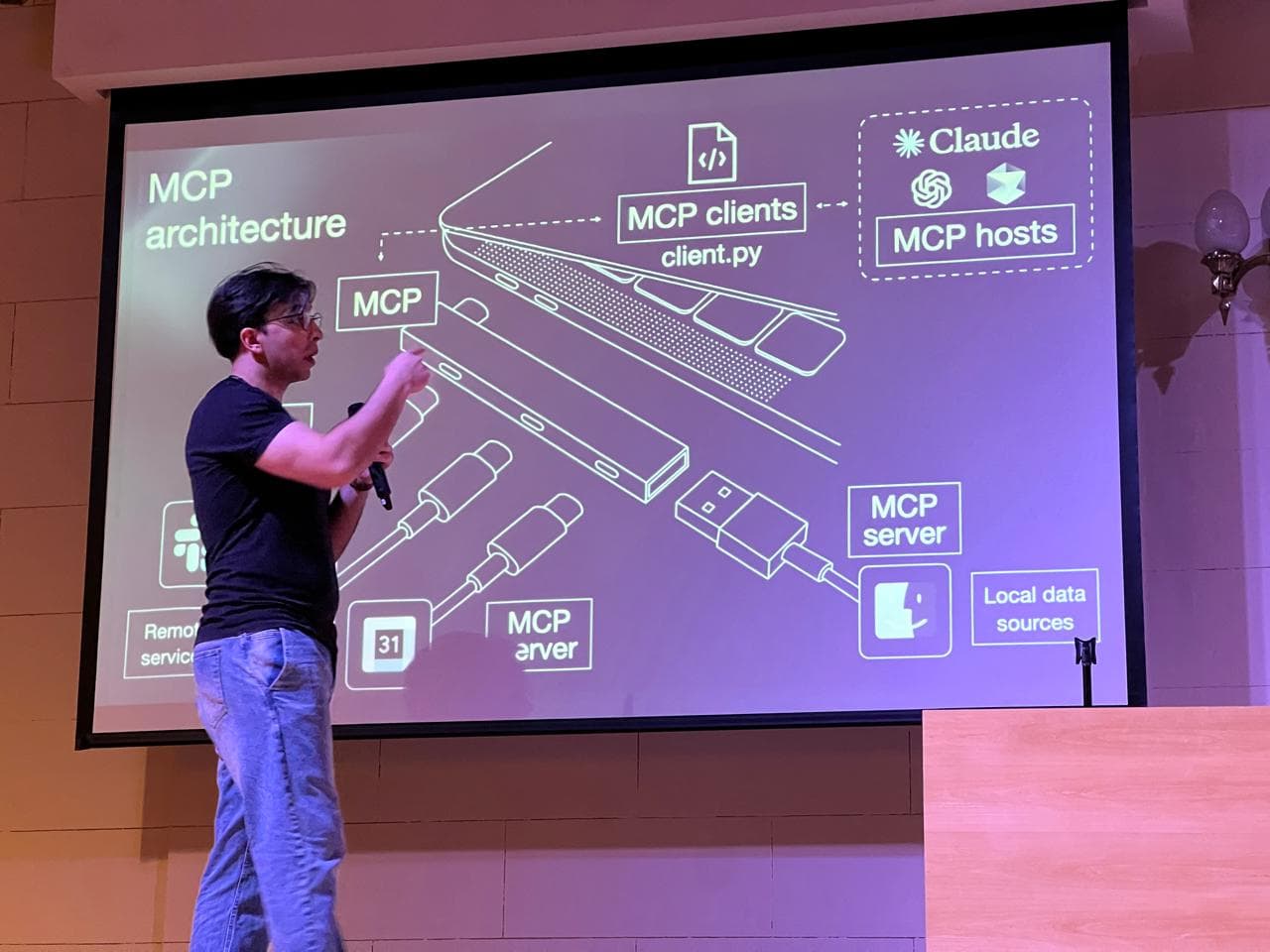
MCP Security for Enterprise Organizations: Experiencias reales y defensa avanzada
Reflexión personal y análisis técnico sobre el protocolo MCP, desde el desafío de presentar a la comunidad hasta los métodos y riesgos reales en AI Security, MCP Server, y defensas recomendadas para organizaciones. Incluye recursos, papers y sitios clave para la investigación moderna en seguridad de agentes AI.
Seguir explorando
Lectura relacionada
Continuá por los temas más relacionados según las etiquetas.

La Anatomía Técnica de la Extracción de Modelos en 2026 (El Gran Robo del Siglo?)
Un análisis técnico profundo sobre los ataques de Extracción de Modelos. Vamos a ver un poco de las matemáticas detrás de la 'Destilación de Conocimiento', los pipelines de recolección de logits y las fallas criptográficas de las marcas de agua en LLMs.
MCP Security for Enterprise Organizations: Experiencias reales y defensa avanzada
Reflexión personal y análisis técnico sobre el protocolo MCP, desde el desafío de presentar a la comunidad hasta los métodos y riesgos reales en AI Security, MCP Server, y defensas recomendadas para organizaciones. Incluye recursos, papers y sitios clave para la investigación moderna en seguridad de agentes AI.

A2AS: Un nuevo estándar para la seguridad en sistemas de IA agéntica
Reflexión, explicación y análisis sobre el paper A2AS, el modelo BASIC y el framework A2AS, desde la perspectiva de los desafíos reales en controles y mitigacion de ataques en AI Security y GenAI Applications.